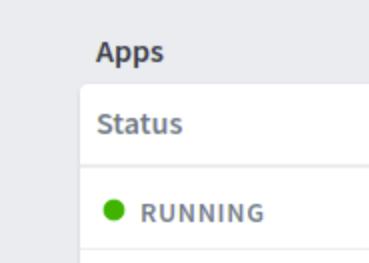
Got Stuff Working
Architected and coded multiple systems that have gotten into production and stayed there

Programmer, Software Architect, IT Leader

Architected and coded multiple systems that have gotten into production and stayed there

Got products and custom software built and live in enterprise organizations across Canada, US and Europe

Proved track record of bring developers together to learn and grow a community. This also includes speaking in conferences like SpringOne to help build the brand product brand and awareness.
Built and managed the creation of a company from the ground up. This included involvement with: hiring, creation of teams, financial and corporate responsibilities, contracts and MSA, grant applications and establishing of strategic partnerships
Luke Shannon, the CEO and co-founder of Phlyt (a Cloud Native consulting company), leverages his international experience and decades of programming experience to develop and train clients in how to build and developing cloud native applications.
Luke’s IT career began in 1999 with iNAGO in Toronto. There, he developed an interactive knowledge base (in the form of an interactive agent) using a platform called Neurostudio and a proprietary programming language called Neuroscript.
Luke’s proficiency using the platform landed him a job with Neuromedia—later known as NativeMinds. With NativeMinds, Luke moved to New York and then San Francisco, working with clients including Ford, Coca-Cola, and American Express. Luke specialized in helping companies create a virtual agent using a NativeMinds proprietary development environment. In 2003, Luke shifted to suite integration work and learned Java.
Luke left NativeMinds in 2004 to work as a Java developer on various freelance projects, including building a chat and IM system for a dating site and a custom CRM platform for the auctioning community in Ontario.
In 2018, Luke left Pivotal to found (along with Christophe Fargette and Lee Stewart) Phlyt, a software company. Phlyt creates, builds, and deploys cloud native projects for complex business environments. Phlyt also specializes in mentoring and training clients who want to build their own cloud native applications.
Today, Luke guides his team of 18 employees in how to develop solutions and coach clients to cloud native success. His handpicked team uses their product expertise and Phlyt client-tailored IP solutions to greatly enhance the client’s platform experience and guide them to success.